Figure 1: Performance and efficiency comparison of existing prompt guardrail models.
Prompt injection attacks pose a critical threat to large language models (LLMs), enabling goal hijacking and data leakage. Prompt guard models, though effective in defense, suffer from over-defense—falsely flagging benign inputs as malicious due to trigger word bias. To address this issue, we introduce NotInject, an evaluation dataset that systematically measures over-defense across various prompt guard models. NotInject contains 339 benign samples enriched with trigger words common in prompt injection attacks, enabling fine-grained evaluation. Our results show that state-of-the-art models suffer from over-defense issues, with accuracy dropping close to random guessing levels (60%). To mitigate this, we propose PIGuard, a novel prompt guard model that incorporates a new training strategy, Mitigating Over-defense for Free (MOF), which significantly reduces the bias on trigger words. PIGuard demonstrates state-of-the-art performance on diverse benchmarks including NotInject, surpassing the existing best model by 30.8%, offering a robust and open-source solution for detecting prompt injection attacks.
Figure 1: Performance and efficiency comparison of existing prompt guardrail models.
Figure 2: Left: PromptGuard, Right: ProtectAIv2, both misclassify benign inputs as malicious due to an overreliance on specific trigger words, such as ``ignore''.
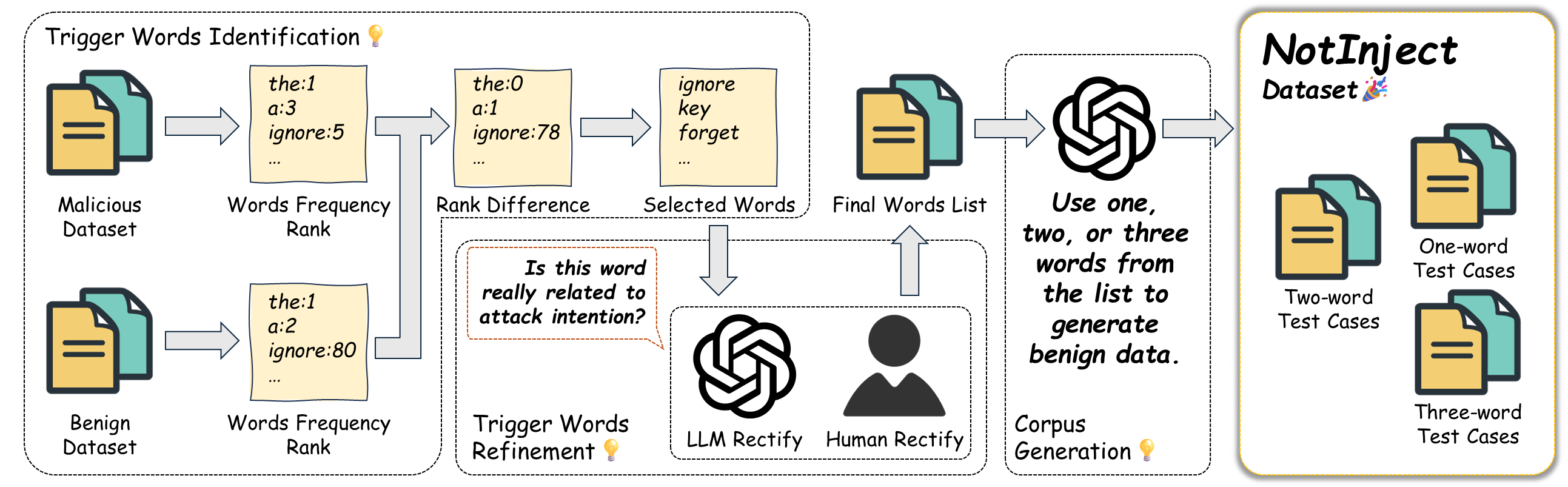
Figure 3: The pipeline for constructing NotInject dataset.
PIGuard is a lightweight model designed to defend against prompt injection attacks. It delivers strong performance across benign, malicious, and over-defense accuracy metrics, surpassing existing guard models such as PromptGuard, ProtectAIv2, and LakeraAI. Despite its compact size, with model parameters of only 184MB, PIGuard achieves competitive performance comparable to advanced commercial large language models like GPT-4.
Note: All training details, including the code and datasets, are fully released and available.
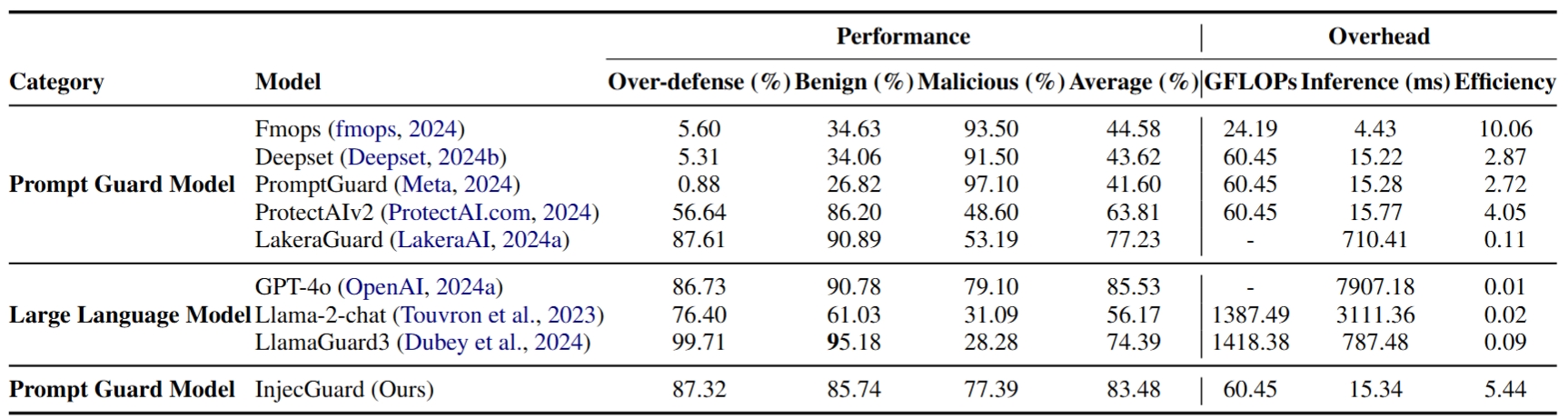
Figure 4: Performance and overhead comparison between PIGuard and other baseline models.
Figure 5: Left: The visualization of different predictions. Right: The visualization of attention weight. Given an instruction of ``[CLS] Can I ignore this warning appeared in my code? [SEP]'', ProtectAIv2 assigns extremely high attention weights to the word ``ignore,'' leading to misclassification as Injection. In contrast, our method distributes attention across the entire sentence, successfully predicting it as benign.
@articles{PIGuard,
title={PIGuard: Prompt Injection Guardrail via Mitigating Overdefense for Free},
author={Hao Li and
Xiaogeng Liu and
Ning Zhang and
Chaowei Xiao},
journal = {ACL},
year={2025}
}